1,3Department of Information Technology, School of Computing, SASTRA Deemed University, Thanjavur, Tamilnadu, India
2Department of Electronics and Communication Engineering, Annamalai University, Chidambaram, Tamilnadu, India
Corresponding author Email: sangita.sudhakar@gmail.com
Article Publishing History
Received: 03/11/2019
Accepted After Revision: 22/12/2019
This paper describes a Hidden Markov Model (HMM) based (TTS) and prosody based (TTS) system for the production of vernacular Tamil Speech. The (HMM) based system contains two phases such as training and synthesis. Tamil speech is first parameterized into spectral and excitation features using Glottal Inverse Filtering (GIF). An emotions present in the input text is modeled depends on the parametric features. The performance measure has been carried out with recorded speech and the (HMM) based (TTS) system. Finally the performance of (HMM) based (TTS) has been compared with different techniques such as the (CSS) based (TTS) approach, prosody based (TTS), TD-PSOLA based (TTS) technique and (FNN) based (TTS) systems to measure the effectiveness of the system. All (TTS) systems are used to analyze the emotions such as Happy, Fear, Neutral and Sad to improve the effectiveness of the system.
Hidden Markov Model (Hmm), Glottal Inverse Filtering (Gif), Text- To- Speech (Tts), Concatenative Syllable Based Synthesis (Css),Time Domain Pitch Synchronous Over Lap Add (Td-Psola), Fuzzy Neural Network (Fnn)
Sangeetha J, Sudhakar B, Venkatesan R. Sentiment Analysis for Expressive Text to Speech Synthesis System Using Different Techniques for Tamil Language. Biosc.Biotech.Res.Comm. 2019;NO2(Spl Issue March).
Sangeetha J, Sudhakar B, Venkatesan R. Sentiment Analysis for Expressive Text to Speech Synthesis System Using Different Techniques for Tamil Language. Biosc.Biotech.Res.Comm. 2019;NO2(Spl Issue March). Available from: https://bit.ly/2Nrcnaq
Introduction
The (HMM) is a successful technique for design the acoustics of speech and it has enabled considerable improvement in speech and language technologies (DoNovan et al.1999; Jurafsky et al. 2000). It is a statistical model used more often for speech synthesis. A basic block diagram of HMM based speech synthesis consists of training and synthesis phase. In the training phase speech signal is parameterized into excitation and spectral features. The HMM is trained using these features. In the synthesis phase, given text is transformed into a sequence of context dependent phoneme labels. Based on the label sequence, a sentence HMM is constructed by concatenating context-dependent HMMs. From the sentence HMM, spectral and excitation parameter sequences are obtained. HMM based speech synthesis has a lot of smart features such as complete data driven voice building, flexible voice quality control, and speaker adaptation. The major advantage of HMM based speech synthesizers is their higher parametric flexibility (Oshimura et al. 2000; Changak et al. 2011).
It is also used to transform voice characteristics, e.g. specific voice qualities and basic emotions. The main characteristics of these systems are High-quality speech and robustness to variations in speech quality. Speaking styles and emotions can be synthesized using a small amount of data. These characteristics make this technique very attractive, especially for applications which expect variability in the type of voice and a small memory footprint (Francisco et al. 2012; Jayasankar et al. 2014 Vibavi et al. 2015).
The naturalness of the CSS based TTS output is evaluated through the comparative performance analysis with respect to the recorded human speech in the noise free environment.The effectivness of the CSS based TTS output is estimated through the comparative performance analysis with respect to the recorded human speech in the noise free environment, ( Recasens et al. 2018).
Prosody refers to the characteristics of speech that make sentences flow in a perceptually natural, intelligible manner. Without these features, speech would sound like a reading of a list of words. The major components of prosody that can be recognized perceptually are fluctuations in the pitch, loudness of the speaker, length of syllables, and strength of the voice. These perceptual qualities are a result of variations in the acoustical parameters of fundamental frequency (F0), intensity (amplitude), phonemic duration, and amplitude dynamics. The pitch and duration play an important role to improve the naturalness of TTS output. The naturalness of the prosody based TTS output is computed through the comparative performance analysis with respect to the recorded human speech in the noise free environment.
The prosody features are combined with TD-PSOLA concatenative technique to smooth and adjust the extreme units of the TTS system. In this system, the speech signal is examined as a series of pitch synchronous short term (ST) signals. These short term signals are then customized, either in the spectral domain or in the the time, in order to find a chain of artificial ST-signals synchronized with a customized pitch contour. Lastly the synthetic speech is attained by overlapped accumulation of the synthetic ST-signal. The preciousness of the TD-PSOLA based TTS output is evaluated through the comparative performance analysis with respect to the recorded human speech in the noise free environment.
Based on the emotions, FNN uses a set of fuzzy rules to classify the sentences to identify the respective emotions. The drawbacks of neural network has been eliminated by FNN incorporated in TTS system. It assigns specific labels for different emotions. Then the suitable emotion based speech output has been generated from the system. The naturalness of the FNN based TTS output is evaluated through the omparative performance analysis with respect to the recorded human speech in the noise free environment.
Material and Methods
Proposed Tts Methods
Hmm based TTS method
The proposed Hidden markov model based Tamil synthesis system aims to construct innate sounding synthesized speech capable of having various sentiments.To attain this objective, the work of true human voice making device is designed by using GIF or Glottal source modeling entrenched in an HMM framework (Sangaransing et al. 2015; Natarajan et al. 2015; Jayasankar et al. 2011).
The motivations to use glottal source modeling in HMM-based speech synthesis are reduce business of synthetic speech,better modeling of prosodic aspects which are related to the glottal source and control over glottal source parameters to improve voice transformations.
Parameterization phase
In parameterization stage, the signal is passed through the high pass filter to reduce the low frequency fluctuation. Then windowing is carried out with 25ms frames at 5ms rectangular window. The log energy is extracted from the windowed flag.At that time speech organ opposite separating is accomplished to appraise the speech organ volume speed from the sound flag. unvaried adaptative Inverse Filtering (IAIF) is employed for the programmed GIF (Tokuda et al. 2013; Vibavi et al. 2015). It iteratively pulls back the impacts of the vocal tract and therefore the lip radiation from the discourse flag, utilizing all-post demonstrating.The proposed work consist of of two main parts: training phase and synthesis phase shown in Fig 1. In the training phase, spectral parameters, namely, Mel Cepstral coefficients and their dynamic features, the excitation parameters, namely, the log fundamental frequency (F0) and its dynamic features, are extracted from the speech data using (GIF).
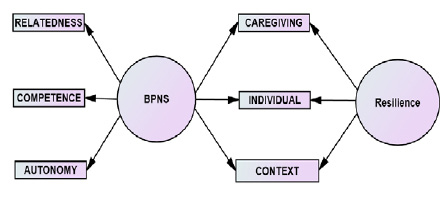 |
Figure 1: A basic block diagram of HMM based speech synthesis |
The HMM is trained using these features. In the synthesis phase, first, an arbitrarily given text is altered into a series of context oriented phoneme labels. Depending on the label sequence, a sentence HMM is created by merging context-dependent HMM. From the sentence HMM, spectral and excitation parameter sequences are obtained based on the Mel Log criterion. The context-dependent phone models are used to capture the phonetic and prosody co-articulation phenomena. Finally, vocoder speech is synthesized from the generated spectral and excitation parameter sequences by concatenating context-dependent HMM. It is used to analyze the emotions such as Happy, Fear, Neutral and Sad to measure the effectiveness of the system.To measure the effectiveness of the system the comparative analysis had been carriedout for HMM with prosody feature modification technique by using the similer emotions (Sudhakar et al.2016).
Concatenative speech synthesis system method
Text analysis
The concatenative based TTS mostly union framework. In content examination, the first stage is content standardization, discharge of accentuations, maybe, double-quotes, full stop(s) and comma(s). Associate in nursing pure sentence is integrated towards the top of content analysis. At that time all of the abbreviations introduced within the info content area unit extended and moreover undesirable accentuations like (:,; $) so forth area unit erased to avoid confusedness and to not provide any aggravation within the natural nature of the discourse. the subsequent stage in content standardization is normalizing nonstandard words like shortened forms and numbers. subsequent stage within the content examination is sentence half. during this stage, the given section is isolated into sentences. From these sentences the words area unit isolated out.
The last stage is Romanization that is that the portrayal of composed words with a roman letter set. during this framework Romanized style of Tamil word or syllables area unit created.
Speech corpus
Development of a discourse corpus for Tamil dialects may be a rather more hard endeavor than that of English discourse corpus. delivery knowledge, maybe, pitch, length and sound forecast should be done throughout the corpus building time. further filtering is also done when the corpus is made. The issue, maybe, error, untranscribed discourse units, categorical limit discovery, delivery variations ar to be distinguished and cared-for. For corpus creation single individual is used for cryptography these essential units and build discourse corpus. The discourse wave records ar spared by the need. The discourse wave records about the Tamil words ar labled by their Romanized names. The words gathered involves lexicon words, unremarkably utilised words, Tamil daily papers and story, books, sports, news, writing and instruction for construction unrestrained TTS framework.
Waveform concatenation
In the last phase of the link procedure, the mandatory syllables are recovered from the corpus in view of the content examination and organized to create the discourse. At that point all the masterminded discourse units are connected utilizing a link calculation. The primary issue in connection process is that there will be abnormalities among the joints. These are expelled in the waveform smoothening stage. The connection procedure joins all the discourse records which are given as a yield of the unit determination process and afterward making in to a solitary discourse document.
Spectral smoothing
The time scale adjustment is completed for every syllable to create singular smoothness for syllable in Tamil TTS. The time scale alteration is utilized to change the pitch, an incentive for Tamil syllable. At that point the length esteem for every syllable ought to be computed. Smoothing at link joints are performed utilizing Linear Predictive Coding (LPC). It is utilized for speaking to the unearthly envelope of an advanced flag of discourse utilizing the data of a direct prescient model. It is a standout amongst the most effective strategies for encoding upgraded excellence discourse at a low piece rate and gives to a great degree precise assessments of discourse highlights. At long last the enhanced quality discourse for the given information content is produced. It can be played and ceased anyplace required. The primary point of the proposed conspire is to accomplish great instinctive nature in yield discourse.
TTS system using prosody features method
This (TTS) framework is constructed as two portions as front end and a back end. The front end has two notable assignments. The front end relegates phonetic translations to each word, and partitions and represents the content into prosodic units, similar to expressions, conditions, and sentences. The way toward doling out phonetic interpretations to words is called content to-phoneme transformation. Phonetic transcriptions and prosody data together make up the emblematic semantic portrayal that is yield by the front end. The back end frequently alluded to as the synthesizer at that point changes over the symbolic etymological interpretation into sound, (Huang et al. 2013; Toma1 et al. 2010 Sangeetha et al. 2017 ).
It presents a TTS synthesis system using prosody features like pitch, pause, stress, phoneme duration, etc.,. First the incoming text must be accurately converted to its phonemic and stress level representations. This includes determination of word boundaries, syllabic boundaries, syllabic accents, and phoneme boundaries. The text preprocessing finds the word boundaries. Subsequently the prosodic parsing involves the determination of phrase boundaries and phrase level accents. Then the system produced appropriate emotions for the text input. Finally concatenation is carried out to produce the synthesized speech output.
TTS system using TD-PSOLA method
It is a notably utilised concatenative synthesis method to create the precious speech signal. The vital aspire of TD-PSOLA method is to modify the pitch directly on the speech waveform (Trilla et al. 2013; Trueba et al. 2015). The TD-PSOLA procedure consecutively used three sequential steps, namel yi) pitch synchronization, ii) pitch synchronization modification and iii) pitch synchronization synthesis. Pitch synchronization showes an vital role on TD- PSOLA method, first one is fundamental frequency detection and second stage is pitch mark.
Let Xn(m) represents the short time signal windowed sequence
Xn(m)=hn(tn−m)y(m) (3)
where tn is the mark point of pitch, hn is the window sequence. Pitch synchronization alteration links the pitch mark by changing the duration (insert or delete the sequence with the length of pitch duration) and tone (increase or decrease the fundamental frequency). The pitch synchronization synthesis adds the novel sequence signal formed in the earlier footstep.

where tj is the new pitch mark, hj is the synthesized window sequence, bj is the weight to compensate the energy loss when modifying the pitch value. The prosody generator received the Tamil text input contents. The prosody generator distribute the duration of each phoneme and the pitch contour.
Initialy the input is transformed into phonemes depends on the key stokes concerned in the font there in the input. A database containing the keywords and category of emotion to which it belong. The text is scanned and the keywords present in the text are the duration and pitch of each phoneme based on the content and context of the text.
FNN based TTS method
The proposed TTS system based on FNN to generate the speech output of various emotions. The lexical analyzer is utilized for changing over the simple text into separate units is known as tokens. These tokens are uttered in normal patterns as recognized by the grammar of the language.
ANTLR (Another Tool for Language Recognition) is an intense parser producer utilized as a part of this system for perusing, handling, executing, or deciphering organized content or binary files. Also it is utilized to decide the content words, refusal words.It is also utilised for sifting the end words in the sentences and to eliminate punctuations and special characters in the sentences.
The sentence splitter divides the entire document into sentences and paragraphs. It utilizes the binary decision for restricting the sentences. Generally upper case letters, periods, question marks and exclamation points are good signs of sentence limits. The denotation of the emotional words (i.e verbs, nouns and adjectives) resolved by sense disambiguator according to their context. It make use of the semantic similarity measure to attain the senses of an emotional word with the background words. Depends on the sentimental attributes the classifier mark remarkable notation to each input text with appropriate emotion. Formatter presents the results in a usable form. Then it is given as input to the phonetic analysis. Tamil language rules are imposed to translate the text to sound waves.
Using a phonetic alphabet Phonetic analysis is utilized to convert the orthographical signs into phonological. The ASCII format text into the sound waves are transulated using grapheme to phoneme transulater. For transulate the Tamil phonetic format syntax and Letter To Sound (LTS) rules have been used. The mixture of stress pattern, rhythm and intonation in a speech is called as prosody. To explain the speaker’s sentiment from end to end pitch variations the prosodic design is mostly used. A deviation of speech while speaking is called Intonation. Ultimatly concatenation is performed to create the synthesized speech.
Results and Discussion
Experimental results of various method for Happy emotions are illustrated in Fig 2. The performance analysis has been carried out through compare the recorded speech with (HMM) based (TTS) system to measure the naturalness achieved in this system.
 |
Figure 2: Different simulated emotional speech like “Happy” for HMM based TTS |
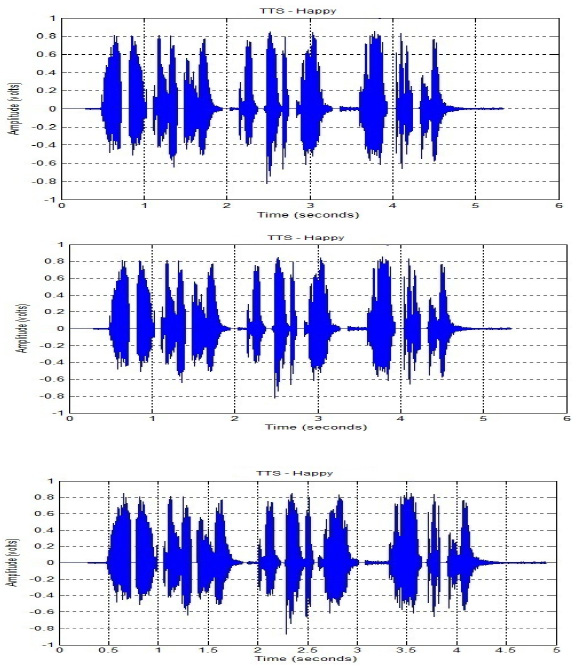 |
Figure 2a |
The recorded speech features are taken from Table-I which are used as the reference for analyze the performance of this system. Table-I shows the amplitude variation and spectral mismatch of recorded speech which is used as the reference to messure the performance of the TTS systems.Because the spectral mismatch is zero it will produce the speech output similar to the natural voice.A highest spectrul mismatch hase been produced in CSS based TTS when compare with the remining methods. Hence the speech out put will not be similar to the natural voice. But the spectal mismatch is minimumin in HMM based TTS system.So the speech signal will be more enhanced in HMM based TTS system when compare with the other TTS methods.
| Table 1: Amplitude variation and spectral mismatch of recorded speech | ||||||||||||
| Emotions | Recorded Speech | CSS | Prosody Parsing | TD-PSOLA | FNN | HMM | ||||||
| Amp
(volts) |
SM (secs) | Amp
(volts) |
SM (secs) | Amp
(volts) |
SM (secs) | Amp
(volts) |
SM (secs) | Amp
(volts) |
SM (secs) | Amp
(volts) |
SM (secs) | |
| HAPPY | 0.95 | 0 | 0.84 | 0.39 | 0.864 | 0.28 | 0.881 | 0.19 | 0.893 | 0.12 | 0.924 | 0.042 |
| FEAR | 0.92 | 0 | 0.83 | 0.43 | 0.842 | 0.37 | 0.863 | 0.28 | 0.871 | 0.16 | 0.892 | 0.063 |
| NEUTRAL | 0.85 | 0 | 0.75 | 0.46 | 0.765 | 0.40 | 0.782 | 0.35 | 0.772 | 0.24 | 0.813 | 0.14 |
| SAD | 0.79 | 0 | 0.64 | 0.49 | 0.67 | 0.43 | 0.693 | 0.38 | 0.714 | 0.32 | 0.752 | 0.19 |
Conclusion
The (HMM) based (TTS) system and (CSS) based (TTS) approach, prosody based (TTS), TD-PSOLA based (TTS) technique and (FNN) based (TTS) systems have been developed for the Tamil language. The performance analysis has been carried out for all systems to measure the naturalness achieved by the individual system. Based on this analysis the (HMM) based system produced highest naturalness than the remining TTS systems. The emotional speech has been generated by (HMM) using the parametric features of (GIF). The prosody feature allows the synthesizer to vary the pitch of voice to produce the output of (TTS) in the same form as if it is actually spoken. The emotions such as “Happy”, “Fear”, “Neutral” and “Sad” are analyzed to measure the effectiveness of the (HMM) based (TTS) systems. Simulation results show that the (HMM) based (TTS) system is gifted by producing precious speech quality.
References
- Changak M.B, Dharskar R.V. (2011), Emotion Extractor Based Methodology to Implement Prosody Features in Speech Synthesis, International Journal of Computer Science, Vol. 08, No. 11, pp. 371–376.
- DoNovan R, Woodland.P.(1999), A Hidden Markov-Model-Based Trainable Speech Synthesizer, Computer Speech Language, Vol.13,No.3,pp.223–241.
- Daniel Recasens., Clara Rodríguez. (2018), An Ultra Sound Study of Contextual and Syllabic Effects in Consonant Sequences Produced Under Heavy Articulatorty Constaint Conditions, Journal of Speech Communications, Vol. 105, No. 02, pp. 34-52.
- Francisco V., Herva˛s R. (2012), Emo Tales: Creating a corpus of folk tales with emotional annotations, Language Resource and Evaluation, Vol. 46, No. 03, pp. 341–381.
- Huang H.E, Lech M. (2013), Emotional Speech Synthesis Based on Prosodic Feature Modification., Engineering, Vol l, No. 5, pp. 73-77.
- Jurafsky D., Martin J.H. (2000), Speech and language processing, Pearson Education, India.
- Jayasankar T., Thangarajan R., Arputha Vijayaselvi J. (2011), Automatic Continuous Speech Segmentation to Improve Tamil Text-to-Speech Synthesis, International Journal of Computer, Vol. 25, No. 1, pp. 31-36.
- Jayasankar T., Arputha Vijayaselvi J., Balaji Ganesh A., Kumar D. (2014), Word and Syllable Based Concatenative Model of Text to Speech Synthesis of Tamil Language,International Journal of Applied Engineering Research, Vol. 9, No. 24, pp. 23955-23966.
- Natarajan V.A., Jothilakshmi S. (2015), Segmentation of Continuous Tamil Speech Into Syllable Like Units, Indian Journal of Science and Technology, Vol. 08, No.17, pp. 417–429
- Oshimura T., Kitamura T.S. (2000), Simultaneous Modeling of Spectrum Pitch and Duration in HMM-Based Speech Synthesis, IEICE Transactions, pp. 2099–2107.
- Sangaransing K., Monica M. (2015), A Marathi HMM Based Speech Synthesys System, Journal of VLSI and Signal processing, Vol. 05, No. 06, pp. 34-39.
- Sudhakar B., Bensraj R. (2016), Performance Analysis of Text To Speech Synthesis System Using Hmm and Prosody Features With Parsing for Tamil Language, International Research Journal of Engineering and Technology, 03, No. 6, pp.2233-2241.
- Sangeetha J., Jayasankar T. (2017), Emotion Speech Recognition Based on Adaptive Fractional Deep belief Network and Reinforcement Learning, Advances in Intelligent Systems and Computing: 167-174.
- Toma1 A., Ionut G. (2010), A TD-PSOLA Based Method for Speech Synthesis and Compression, Proceedings of IEEE International Conference on Communications, 23–126.
- Trilla T., Alias F. (2013), Sentence-Based Sentiment Analysis for Expressive Text-to-Speech, Proceedings of IEEE Transactions on Audio and Speech and Language Processing, 223–233.
- Tokuda K., Nankaku Y. (2013), Speech Synthesis Based on Hidden Markov Models, Proceedings of IEEE, Vol. 101, No. 5, pp. 1234–1252.
- Trueba J.L. (2015) Emotion Transplantation Through Adaptation in HMM-Based Speech Synthesis, Computer Speech Language processing, 34, No. 01, pp. 292-307.
- TobiasJ., DanieleG. (2016), Fast Algorithms for High Order Sparse Linear Prediction With Applications to Speech Processing, Speech communication, Vol. 76, No. 01, pp.143–156.
- Vibavi R., Bharath G. (2015), Text Processing for Developing Unrestricted Tamil Text to Speech Synthesis System,Indian Journal of Science nd Technology,Vol. 08, No. 29, pp.112-124.
- Vibavi R., Bharath G. (2015), Text processing for Developing Unrestricted Tamil Text to Speech Synthesis System, Indian Journal of Science and Technology, Vol. 08, No. 29, pp.112-124.

