1,2,4Department of Information Technology, Faculty of Computing & Information Technology, King Abdulaziz University, Jeddah, Saudi Arabia
3 Faculty of Education, University of Jeddah, Jeddah, Saudi Arabia
5,6Department of Computer Science, Faculty of Computing & Information Technology, King Abdulaziz University, Jeddah, Saudi Arabia
Article Publishing History
Received: 09/05/2019
Accepted After Revision: 25/06/2019
This paper presents an intelligent model to read, understand and translate Arabic text content into Arabic signs. The proposed model includes four main phases, preprocessing, modeling language, translation, and sign generation phases. In the preprocessing phase, the corpora and the stop words will be employed. The language model includes morphological, lexical and syntax, and semantic analysis. This is in addition to stem, root extraction with ontological support, and number indication will be involved. Consequently, we have different features that represent the analyzed Arabic text (words’ meanings, words ordering, syntactic features, number features …). Therefore, the generation phase takes place to generate the equivalent Arabic signs using the signer model. Accordingly, the deaf and hearing-impaired people are showing the generated stream of Arabic signs using video or 3D Avatar. The proposed solution uses programming corpus written in Arabic language, so the generated dictionary/lexicon has limited set of Arabic words with their meaning. After getting the content data from the course, the language model analyzes and understands the content and store it into deep structure or internal representation, consequently, the system will generate the Arabic stream signs based on the signer model.
Arabic Nlp, Corpus, Deaf, Hearing-Impaired, Machine Translation
Al-Barhamtoshy H. M, Abuzinadah N. E, Nabawi A, Himdi T. F, Malibari A. A, Allinjawi A. A. Development of an Intelligent Arabic Text Translation Model for Deaf Students Using State of the Art Information Technology. Biosc.Biotech.Res.Comm. 2019;12(2).
Al-Barhamtoshy H. M, Abuzinadah N. E, Nabawi A, Himdi T. F, Malibari A. A, Allinjawi A. A. Development of an Intelligent Arabic Text Translation Model for Deaf Students Using State of the Art Information Technology. Biosc.Biotech.Res.Comm. 2019;12(2). Available from: https://bit.ly/2QMOMz1
Copyright © Al-Barhamtoshy et al., This is an open access article distributed under the terms of the Creative Commons Attribution License (CC-BY) https://creativecommns.org/licenses/by/4.0/, which permits unrestricted use distribution and reproduction in any medium, provide the original author and source are credited.
Introduction
Now a day, disability, deaf-blind, and hearing-impaired need a communication way to deal with teaching and communicating the community and society. The communication approach is to find the best way to speak, understand, visualize and deal what they are need. Sign language is the most effective way to communicate with those people. Sign language used for deaf and hearing-impaired people in order to facilitate the communication with community people (Abuzinadah, et al., 2017). A sign language recognition based on deep learning methodology from video sequences is proposed in (Konstantinidis, et al., 2018) and (Kong & Ranganath, 2008). However, face expression, two hands gestures and body language have been introduced to adopt the recognition and generation tasks with deaf and hearing-impaired (Lim, et al., 2016).
Other challenge point to work with the sign language is the dataset needed to work with sign recognition and sign generation. Some of this dataset uses only one hand (right hand), and others are signed with both hands, (Konstantinidis, et al., 2018) (Ronchetti, et al., 2016). Hand gestures provide important information to work with sign languages such as ASL, FSL, DSL, RSL and also Arabic Sign language (ArSL) (Patel & Ambekar, 2017) (Nikam & Ambekar, 2016) .
A more recent development in the academic, pedagogic and societal is a demand for legal recognition to emerge the hearing-impaired people into society (Harris, 2018). Therefore, sign languages are faced number of challenges related to socio-linguistic aspects for signing with the community (Quer & Steinbach, 2019).
Video Apprach
A bilingual corpus for Arabic sign language has been created in (ElMaazouzi, et al., 2016) concerned with developing a corpus for sign language that meets communication needs of the Arab deaf community. An alternative approach is presented to use video technology in Insign project to answer an online survey from 84 deaf over 22 diverse countries (Napier, et al., 2018). A deep learning method used to analyze and recognize video in sign language (Konstantinidis, et al., 2018) based on framework. In such work, video is examined and analyzed using images flow extracted features, and skeletal movement features (body, hand and face), in such case, each signed video corresponds separate word.
3D Avatar Approach
An assistant education model with 3D avatar is presented in (Ulisses, et al., 2018) to incorporate Virtual Sign as a translator between sign language and oral language.In last decade, an example-based approach is implemented as a translator in American Sign language (ASL) with a deaf people (Morrissey & Way, 2005). In addition, leap motion can be converted and therefore, translated into text using assistant device such as tablet machine (Escudeiro, et al., 2017).
Simov (Simoy, et al., 2016) presented semantic-based approach to translate from Bulgarian and English in information technology domain. This approach is used for answering questions after employing of morphological analysis for Bulgarian nature. Some troubles and difficulties such as understanding the concept and the meaning of programming terminologies and related definitions need to additional elaboration. The idea behind that is, lexical units that have similar meanings should appear in similar context. Therefore, official repository for semantic information for course contents and terminologies definitions will be involved.
Machine Translation Framework
A simple prototype framework for translate Arabic text content to Arabic sign language using video or 3D avatar will be described in this section. The framework of the proposed model accepts any Arabic text content and analyzes and understands such content and store such meaning into a deep structure or internal representation. The architecture of the proposed framework is illustrated in Fig 1. The proposed solution of ArSL signer based on rule and lexical-based approaches. It uses morphology phase and syntax phase in dependency trees, without any sophisticated methods (machine learning algorithms).
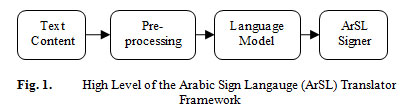 |
Figure 1: High Level of the Arabic Sign Langauge (ArSL) Translator Framework |
Preprocessing Model
The proposed solution starts with retrieving Arabic text content, cleaning and preprocessing text data with analyzing, understanding with ways of language processing algorithms. Therefore, the “Arabic text content” must be aggressively filtered and corrected from obvious typos. So, syntactic analysis and semantic analysis will be explored. So, many NLP procedures will be involved, i.e.; word tokenization, stemming, POS tagging, word meaning, topic model or ontology model. Therefore, in this chapter various fundamentals in Arabic NLP coupled with other state of the art techniques will be covered.Consequently, the “Arabic text content” includes “Arabic stop words”, we need to remove these stop words before Arabic text analysis and understand. This in addition to make some corrections of the “Arabic text content”. After removing “stop words”, the language model takes place to tokenize the “Arabic text content” stream before the POS tagger model.
Language model
The objective the language model is to analyze and understand the content text in order to extract the relevant information and create the internal features’ representation of the analyzed text. This internal representation is very important to generate the equivalent of the signs of the Arabic sign language (ArSL). In this part, we are going to cover several procedures to process the Arabic text content along with examining content analysis. Therefore, ways of techniques to analyze and understand the Arabic content: text cleaning and text normalization, stop words removing, word tokenization, word stemming, and POS tagging. Consequently, the task of the language model includes several phases, tokenizer, morphological, syntactic and semantic analysis phases. Therefore, the language model uses a well-defined dictionary, lexicon and grammatical rules. The output results of the language model are used to achieve the internal deep structure (internal representation).
Phrase treatment and Arabic Grammar
The first step includes two entirely steps: sentence/phrase splitting and word derivations with affixes processing. Any Arabic text content will be segmented into separate sentences/ phrases (chunks). The Arabic phrases are classified into noun phrases (NP) or verb phrases (VP). We can extract the noun phrases from the Arabic text content, and consequently, identify noun, proper noun, and extra noun phrase from the text.

The Arabic grammar is flexible with phrase and sentence structure in word ordering. The simple Arabic phrase has three forms (read from right to left):
- (فهم الطالب البرنامج)
- (الطالب فهم البرنامج) < Verb: فهم > < Subject: الطالب>
- (البرنامج فهمه الطالب)
In English, the phrase might be (Student understood the program) =>
Tokenizer Phase
After that, each sentence/phrase will be segmented into separate words (tokens). So, the morphological analyzer takes place to analyze and make derivations of the current word and remove affixes from it, and therefore, find root, stem, prefix, suffix, and infix (if it is existing). The affixes is processed to find out additional parameters or indictors to support the word type (verb, noun, character, etc.), gender, tense for verb, number “singular or plural” (Al-Barahamtoshy & Al-Barhamtoshy, 2017) (Al-Barhamtoshy, et al., 2014). Details of the preprocessing phase and the details of tokenizer module are shown in Fig 2 (Al-Barhamtoshy, et al., 2007). Arabic text content as inputting will be translated into stream of signs.
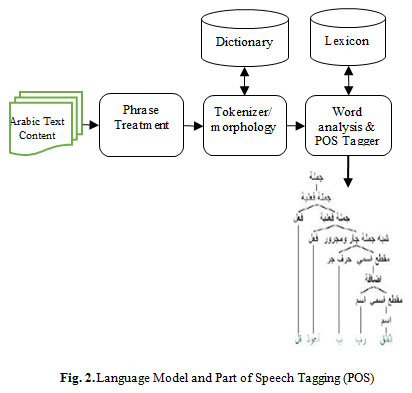 |
Figure 2: Language Model and Part of Speech Tagging (POS) |
Ontology Phase
The ontology term is used to describe conceptualization of linguistic terms for representing entities in the domain. Other researchers are using ontology as resources of knowledge to measure the semantic similarity between analyzed tokens.
We are now moving from corpus data (unstructured data that includes programming contents) to deep structure or internal representation (semi structured data). If we know the course author name, we also know that author lives in country; author write books that are published on certain dates and written in a particular language, etc. There is a whole series of information to be drawn from this story scenario- this is the goal of the ontology. In addition, phonology helps us understand missing data. If the NLP analyst has realized the author and title, what has not been recognized? It seems that the book is published in programming domain. So let’s look for history – it’s there. Moreover, it seems that the language is also involved – we can find it too.
This section presents additional formal linguistic information about word meaning (Arabic ontology). This formal representation describes the concepts of the Arabic programming terms within the course description. The formal representation includes terms concepts and their semantic relationships (see Fig. 3).
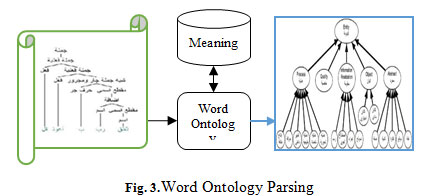 |
Figure 3: Word Ontology Parsing |
The detailed design of the complete proposed solution is illustrated in Fig 4. We are now moving from corpus data (unstructured data that includes an introduction for Java programming contents) to deep structure or internal representation (semi structured data).
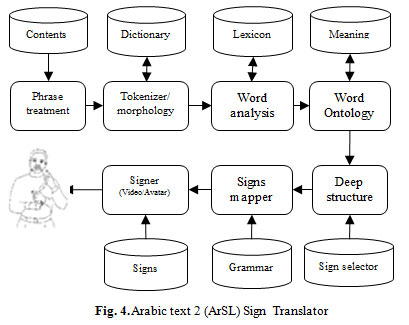 |
Figure 4: Arabic text 2 (ArSL) Sign Translator |
The ontology provides semantic information about the analyzed words. Thus, the system performs “word sense disambiguation” (WSD) using the analyzed part of speech (POS) for deciding best notation. Therefore, an ontology-based in the information technology domain is created. It is used to enhance the semantic accuracy in the Arabic-signs translation. The syntactic analysis is done first (Al-Barahamtoshy & Al-Barhamtoshy, 2017) (Al-Barhamtoshy, et al., 2014) using Arabic grammatical rules (Al-Barhamtoshy, et al., 2007)].
Ontology Domain
The deep structure of the analyzed Arabic text is used to generate ontology programing domain. The proposed ArSL translator is mainly intended to provide translation process of the “primary programming content” to stream of Arabic signs at KAU university using both the two methodologies (video and Avatar). Therefore, SQL database can be used to generate the output stream using RDF, OWL and XML (visual ontology design). Fig 5 illustrates relation between the analyzed text content (internal/deep features’ structure) and the visual ontology design module.
Sign Language Dictionary and the Signer
Many of bilingual dictionaries have been designed to support several sign languages over the world (Bouzid & Jmni, 2017). Each of these dictionaries tries to search and find the equivalent signs.
In this paper, we will use two methodologies of dictionary building. The first methodology is the video and written word utterance equivalent. The second is the sign written word with Avatar transcription. The ArSL translator try to find the video/avatar equivalent with the analyzed Arabic text. The only thing we need is large data. However, depending on how we plan to use our model, we need to be more or less satisfied about the quality of the dictionary and lexicon we use. When in doubt, the general rule is the more data we have, is the better.
Moreover, depending on the corpus size (text content), training can take several hours or even days, but fortunately we can store the analyzed data and extracted features on a storage disk. This way we do not have to do the analyzed tasks of model training every time we need to use it.
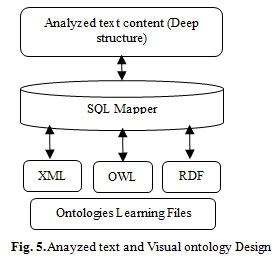 |
Figure 5: Anayzed text and Visual ontology Design |
The solution takes the analyzed deep structure of the analyzed text and converts this structure into RDF using OWL and XML. Therefore, if ontology (repository) signer is ready with semantic concepts, the signer is ready to translate.
Corpora Creation
Many courses related to programming can be used to create dataset (dictionary and lexicon) of the proposed solution with the Arabic Sign Language (ArSL). The generated video terms with our corpus includes 149 samples. Table 1 and table 2 illustrate some examples that are selected from the created corpus. The following equations describes the tree domain of corpus regular expression that, includes our proposed corpora.

Table 1: Arabic Computational Terms with English Equavalent Data Examples
| Terms | Rating | Terms | Rating | ||
| Arabic | English | (1,2,3) | Arabic | English | (1,2,3) |
| عتاد | Hardware | 3 | لغة برمجة | Language | 3 |
| برمجيات | Software | 2 | جافا | Java | 3 |
| تطبيق | Application | 3 | سي++ | C++ | 3 |
| برنامج | Program | 3 | وورد | Word | 3 |
| نظام تشغيل | Operating system | 3 | تصميم برنامج | Program Design | 2 |
| ويندوز | Windows | 3 | ترجمة برنامج | Program Compiling | 2 |
| يونكس | Lunix | 2 | نسخة احتياطية | Backup | 3 |
| أندرويد | Android | 3 | ملف | File | 3 |
| ذاكرة | Memory | 3 | سجل | Record | 3 |
| ذاكرة عشوائية | RAM | 3 | يحلل | Parse | 3 |
| حزمة | Package | 3 | خصائص | Properties | 3 |
| عام | Public | 3 | خاص | Private | 1 |
| قواعد | Syntax | 3 | اختبار | Test | 3 |
| تسمية | Label | 3 | رابط | Link | 3 |
| مفكرة | Notepad | 3 | تنفيذ | Execute | 2 |
| صحيح | True | 3 | مشغل | Operator | 3 |
| خطأ | false | 3 | تتبع | Trace | 3 |
The equations in 7, 8, and 9 illustrate the different regular expression (in BNF grammars) to formulate the ArSL derivation grammars.
Table 2: ArSL Definitions Examples
| SN | Original Content Topics | Rating (1,2,3) | ||
| English | Arabic | Video | Avatar | |
| 1 | Computer Compnents | مكونات الحاسوب | 3 | 3 |
| 2 | Hardware | المكونات المصنعة (العتاد) | 3 | 3 |
| 3 | Software | برمجيات أو تعليمات | 2 | 2 |
| 4 | Program Definition | تعريف البرنامج | 2 | 2 |
| 5 | Operating System | نظام التشغيل | 3 | 3 |
| 6 | Compiler | مترجم اللغة | 3 | 3 |
| 7 | Java Language | لغة جافا | 3 | 3 |
| 8 | Java Advantages | مميزات لغة جافا | 2 | 2 |
| 9 | IDE | بيئة التطوير المتكاملة | 2 | 3 |
| 10 | JDK | مكتبة تطوير جافا | 3 | 3 |
The ArSL language is a derivative of spoken-written Arabic language, and therefore it is not a language by itself. This in addition to reordering of the signs or the position of signs. Such position or reordering of the signs’ criteria will be taken into consideration, table 3 illustrates the word evaluation form, according to position or reordering of 10 Arabic signs.
Table 3: Dataset Subset of Control Statements Evaluation Form
| SN | Arabic Word | English Word | Rating (1,2,3) | |
| Video | Avatar | |||
| 1 | حزمة | Package | 3 | 3 |
| 2 | فئة/صفيفة | Class | 3 | 3 |
| 3 | أمرالشرط إذ | If | 3 | 3 |
| 4 | أمر شرط إذ وإلا | If … else | 3 | 3 |
| 5 | أمر التكرار من | For | 3 | 3 |
| 6 | أمر حاول | Try … Catch | 3 | 2 |
| 7 | أمر حالة.. مفتاح | Switch … Case | 3 | 3 |
| 8 | توقف | Break | 3 | 3 |
| 9 | إفعل | Do | 3 | 3 |
| 10 | طالما/مادام | While | 3 | 3 |
Testing and Evaluation
To test and evaluate the proposed “Arabic Text to Arabic Signs” translation system, a human effort is used with respect to the equivalent translated signs. There are evaluation metrics that used to measure the quality between different machine translation solutions, but they are not used in sign translation. Therefore, an evaluation sheet has been prepared, includes the 10 technological translated definitions in the proposed dataset of the ArSL. Table 4 illustrates the proposed evaluation form.
Word Error Rate (WER) is used to evaluate machine translation and automatic speech recognitions (Al-Barhamtoshy, et al., 2014). The WER criterion based on the following:
WER = ( I + D + S ) / N .………. (10)
Where N represents total words in the dataset, I represents the number of words/signs that are inserted, D is the number of words/signs that are deleted, and S is the number of substituted words/signs in the translation process.
The WER is implemented based on the Levenshtein distance for words matching between original content (Java course) and the signed content (signed by ArSL).
Table 4: Meaning Dataset Subset of ArSL Evaluation Form
| SN | Arabic Meaning Definition Terms | Word Error Rate | |
| Video | Avatar | ||
| 1 | مكونات أجهزة الحاسوب | 0 | 0 |
| 2 | مجموعة من المكونات المصنعة (العتاد) | 0.2(1/5) | 0.2(1/5) |
| 3 | مجموعة برامج أو تعليمات تشغل الكمبيوتر | 0.3(2/6) | 0.3(2/6) |
| 4 | مجموعة أوامر، تكتب وفق قواعد تُحَدَّد بواسطة لغة برمجة، ثم تمر هذه الأوامر بعدة مراحل وتنفذ على الحاسب | 0.3(6/18) | 0.33(6/18) |
| 5 | أحد مكونات البرمجيات الذي يقوم بتفسير التعليمات ومعالجة البيانات عن طريق الحاسب. | 0.24(3/12) | 0.26(3/12) |
| 6 | مترجم اللغة | 0.5(1/2) | 0.5(1/2) |
| 7 | لغة جافا | 0 | 0 |
| 8 | مميزات لغة جافا | 0.3(1/3) | 0.3(1/3) |
| 9 | بيئة التطوير المتكاملة | 0.3(2/3) | 0.3(2/3) |
| 10 | مكتبة تطوير جافا | 0 | 0 |
Red color means that these words (characters) are not signed.
Therefore, the accuracy is computed by:
Accuracy = (1-WER) x 100 ……………………… (11)
The ArSL prototype system is implemented in Python language. The following figures (Fig 6 (a):(f)) and (Fig 7 (a): (f)) are the outputs of the two proposed models (video and Avatar).
 |
Figure 6: Evaluated samples of output results for the Video approach |
Next, we compare between the two models’ video and avatar, using the predefined corpora. The deaf human expert evaluates each corpus’ word by word using the created dataset. Table 4 describes the evaluation processes of the proposed dataset, considered word error rate (WER), sensitivity, and specificity.
Table 5: Dataset Subset of ArSL Evaluation Form
| Video Model | Avatar Model | ||||
| WER(I+D+S)/N | SensitivityP/(P+N’) | SpecificityN/(N+P’) | WER(I+D+S)/N | SensitivityP/(P+N’) | SpecificityN/(N+P’) |
| 0 | 1.0 | 1.0 | 0 | 1.0 | 1.0 |
| 0.2 | 0.96 | 0.94 | 0.2 | 0.96 | 0.94 |
| 0.3 | 0.94 | 0.95 | 0.3 | 0.94 | 0.95 |
| 0.30 | 0.92 | 0.90 | 0.33 | 0.95 | 0.91 |
| 0.24 | 0.94 | 0.93 | 0.26 | 0.93 | 0.92 |
| 0.5 | 0.91 | 0.92 | 0.5 | 0.91 | 0.92 |
| 0 | 1.0 | 1.0 | 0 | 1.0 | 1.0 |
| 0.33 | 0.91 | 0.92 | 0.33 | 0.91 | 0.92 |
| 0.33 | 0.90 | 0.93 | 0.33 | 0.90 | 0.93 |
| 0 | 1.0 | 1.0 | 0 | 1.0 | 1.0 |
P = True positive value, N = True negative value.
P’= False positive value, N’= False negative value.
We analyzed the proposed corpora: Arabic text content corpus, video corpus and avatar corpus. We collected the errors, and then classified them into the two using approaches video and avatar. Table 4 illustrates the details of the evaluated work achieved by human experts. Therefore, the table demonstrates the WER, precision, and recall of the proposed translation using the two approaches. We found no significant difference between the two approaches video and avatar for the Arabic sign translation. Also, no statistically differences between the two approaches for precision and recall. The overall evaluation analysis of the output result demonstrates the effectiveness of our two approaches using the proposed translation solution of the Arabic text content to the Arabic sign language.
The accuracy performed through two experiments. Experiment # 1 using evaluator procedure with human experts using WER to measure the errors in the generated Arabic sign results. We selected the original course text content compared to the generated (translated) signs output using ArSL. Fig. 5(a) illustrates the WER for the two approaches. Experiment #2 describes the precision and recall for the used corpora using the two approaches video and avatar.
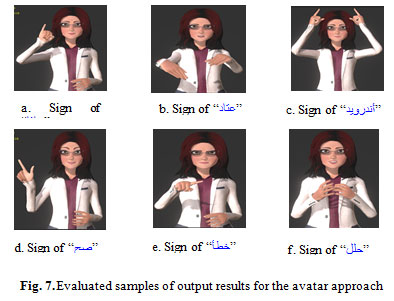 |
Figure 7: Evaluated samples of output results for the avatar approach |
Fig 8 displays the comparison between the two approaches for the WER and the precision and recall for the evaluation form.
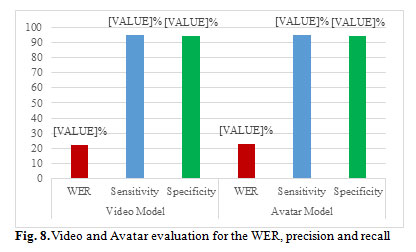 |
Figure 8: Video and Avatar evaluation for the WER, precision and recall |
Experimental Testing
In real test, the ArSL corpus includes 150 of video signs stream in the domain of Java programming. It consists from 55 video for computational terms, 50 videos signs for reserved terms, and 45 terms for control and conditional statements. The ArSL signer test shows the number of correct and non-correct for deaf people at the committee student test (Table 6).
Table 6: Number of Correct and Non-Correct During Signer Pronounciation Test
| Computational | Reserved | Conditional | |
| Correct | 51 | 48 | 40 |
| Non-Correct | 4 | 2 | 5 |
| WER | 7.27 % | 4.00 % | 11.11 % |
| Average WER | 7.46 % | ||
The total average value of WER for the sign understanding is derived with the proposed approach on the perception of the conducted human expert. The experimental results show that the WER for signing of (1) computational-terms is 7.27%, (2) for Java reserved words (terms) is 4.00%, and (3) for control and conditional statement is 11.11%. The overall WER for the proposed work is 7.46 %.
Performance Testing
In order to evaluate the speed of the proposed system, performance testing is done. Table 7 illustrates the performance testing results, during playing every term.
Table 7: Performance Testing Results
| ArSL Terms | Average time (Second) | Average File size (MB) |
| Computational Term | 3.0 | 3.150 |
| Reserved Terms | 1.2 | 1.750 |
| Control and Conditional Terms | 2.1 | 2.675 |
Conclusion
We have presented in this paper, a proposed machine translation model to translate from Arabic text content to Arabic sign language (ArSL). The real application domain includes an introduction to Java programming in the secondary school for deaf and hearing-impaired students. The solution build two corpus/corpora for Arabic sign language, one for avatar and second for real video in scope domain of programming.
This is the first corpora in Arabic sign language that covered the programming domain. Two prepared corpora approaches are implemented, one for video model and the second for Avatar model. The two models are used in translation for deaf and hearing-impaired children. For this purpose, 100 video and 100 avatars were tested and evaluated.
An expert human assessed manually, the two corpora of the proposed work. Then, this evaluator measured improvement according to the information technology and programming domain.
Future work will include well-known bilingual dictionaries/lexicons with mapping process to RDF and OWL for content translation. In addition, BLEU will be involved as metric to evaluate the meaning in the output result of the proposed system.
Acknowledgement
The authors would like to pay special thanks to Ms. Khadija Kidwai for her valuable assistance during the research process.
References
Abuzinadah, N., Malibari, A. & Krause, P., 2017. Towards Empowering Hearing Impaired Students’ Skills in Computing and Technology. International Journal of Advanced Computer Science and Applications, 8(1), pp. 107-118.
Al-Barahamtoshy, O. & Al-Barhamtoshy, H., 2017. Arabic Text-to-Sign (ArTTS)Model from Automatic SR System. Procedia Computer Science, Volume 117, pp. 304-311.
Al-Barhamtoshy, H., Abdou, S. & Jambi, K., 2014. Pronunciation Evaluation Model for Non-Native English Speakers.. Life Science Journal, 11(9), pp. 216-226.
Al-Barhamtoshy, H. et al., 2014. Speak Correct: Phonetic Editor Approach. Life Sience, 11(9), pp. 626-640.
Al-Barhamtoshy, H., Saleh, M. & Al-Kheribi, R., 2007. Infra Structure for Machine Translation. Cairo, The Seventh Conference for Language Engineering.
Al-Barhamtoshy, H., Thabit, K. & Ba-Aziz, B., 2007. Arabic Morphology Template Grammar. Cairo, The Seventh Conference on Language Engineering, Ain Shams University..
Bouzid, Y. & Jmni, M., 2017. ICT-based Applications to Support the Learning of Written Signed Language. s.l., 6th International Conference on Information and Communication Technology and Accessibility (ICTA).
ElMaazouzi, Z., El Mohajir, B., Al Achhab, M. & Souri, A., 2016. Development of a Bilingual Corpus of Arabic and Arabic Sign Language based on a Signed Content. s.l., 4th IEEE International Colloquium on Information Science and Technology (CiSt).
Escudeiro, P. et al., 2017. Digital Assisted Communication. s.l., Proceedings of the 13th International Conference on Web Information Systems and Technologies .
Harris, R., 2018. Transforming My Teaching Through Action Research. Journal of American Sign Languages and Literatures. Deaf Eyes on Interpreting ed. Washington, DC: Gallaudet Press.
Kong, W. & Ranganath, S., 2008. Signing Exact English(SEE) Modeling and Recognition. Pattern Recognition, 41(5), pp. 1638-1652.
Konstantinidis, D., Dimitropoulos, K. & Daras, P., 2018. A Deep Learning Approache for Analyzing Video and Skeletal Features in Sign Language Recognition.. s.l., IEEE International Conference on Imaging Systems and Techniques.
Konstantinidis, D., Dimitropoulos, K. & Daras, P., 2018. Sign Language Recognition on Hand and Body Skeletal Data, s.l.: European Union.
Lim, K. M., Tan, W. C. & Tan, S. C., 2016. A Feature Covariance Matrix with Serial Particle Filter for Isolated Sign Language Recognition. Expert Systems and Applications, Volume 54, pp. 208-218.
Morrissey, S. & Way, A., 2005. An example-based approach to translating sign language. Structure, pp. 109-116.
Napier, J. et al., 2018. Using Video Technology to Engage Deaf Sign Language Users in Survey Research: An Example from the Insign Project.. The International Journal for Translation & Interpreting Research, 10(2), pp. 101-122.
Nikam, A. & Ambekar, A. G., 2016. Bilingual Sign Recognition using Image Based Hand Gesture Technique for Hearing and Speech Impaired People. s.l., Second International Conference on Computing, Communication, Control & Automation.
Patel , U. & Ambekar, A. G., 2017. Moment Based Sign Language Recognition for Indean Language. s.l., Third International Conference on Computing, Communication, Control and Automation (ICCUBEA).
Quer, J. & Steinbach, M., 2019. Handling Sign Language Data: The Impact of Modality. Front. Psychol. 10:483. doi: 10.3389/fpsyg.2019.00483 ed. Barcelona, Spain: Autonomous University of Barcelona, Spain.
Ronchetti, F. et al., 2016. LSA64: A Dataset of Argentinian Sign language. s.l., Congreso Argentino de Ciencias de la Computacion (CACIC).
Simoy, K., Osenova, A. & Popov, A., 2016. Towards semantic-based hybrid machine translation between Bulgarian and Engish. In: Proceedings of the 2016 Conference of the North American Chapter of the Association fo Computational Linguistics: Human Language Technologies. s.l.:s.n.
Ulisses, J. et al., 2018. ACE Assisted Communication for Education: Architecture to Support Blind & Deaf Communication. Canary Islands, IEEE Global Engineering Education Conference (EDUCON).

