1,3Department of Information Technology, Faculty of Computing & Information Technology, King Abdulaziz University, Jeddah, Saudi Arabia
2Department of Information Technology, University of Jeddah, Jeddah, Saudi Arabia
Article Publishing History
Received: 05/04/2019
Accepted After Revision: 20/06/2019
This paper presents an intelligent model to analyze, understand and classify Arabic tweets. The proposed model includes four main phases; preprocessing, feature extraction, language model, and classification model phases. In the preprocessing phase, the corpora and the stop words will be employed. The language model includes morphological, lexical, syntax, and semantic analysis. Moreover, stem, root extraction and number indication will be involved. Consequently, we have different features that represent the analyzed Arabic tweets (meanings, word order, syntactic features, number features …). Therefore, the classification phase is used to classify Arabic tweets model. The proposed solution uses tweets corpora written in Arabic, so the generated dictionary/lexicon has been made of Arabic words with their meaning. After getting the content data from the corpora, the language model analyzes and understands the content and stores it into deep structure or internal representation. Therefore, feature extraction extracts tweets features, and classification model classifies the new tweets. This study uses linguistic preprocessing tasks and similarity functions to outperform Arabic tweets clustering. Consequently, machine learning will generate the result of the analyzed tweets.
Arabic Tweets, Machine Learning, Corpus, Sentiment Analysis
Al-Barhamtoshy H. M, Hemdi H. T, Khamis M. M, Himdi T. F. Semantic and Sentiment Analysis for Arabic Texts Using Intelligent Model. Oryzae.Biosc.Biotech.Res.Comm. 2019;12(2).
Al-Barhamtoshy H. M, Hemdi H. T, Khamis M. M, Himdi T. F. Semantic and Sentiment Analysis for Arabic Texts Using Intelligent Model. Biosc.Biotech.Res.Comm. 2019;12(2). Available from: https://bit.ly/2KscMaf
Copyright © Al-Barhamtoshy et al., This is an open access article distributed under the terms of the Creative Commons Attribution License (CC-BY) https://creativecommns.org/licenses/by/4.0/, which permits unrestricted use distribution and reproduction in any medium, provide the original author and source are credited.
Introduction
Arabic is the main language in the Middle East; therefore, it is the language of a large number of posted messages in social media applications. Arabic is the most growing language over the web. Millions of messages and followers in Arabic are posted daily in social media. However, Arabic still suffers deficiency to analyze and extract valuable knowledge. Sometimes, dialectal and modern standard Arabic may be used in different Arabic countries. Recently, short text messages in social media, such as Facebook posts as well as Twitter tweets have been increasing. Therefore, opinions analysis, subject clustering, and messages classification are used to extract valuable knowledge such as sentiments, products, services and different events. Many researches handle tweets sentiment analysis, (Abuaiadah, et al., 2017) (El-Nagga, et al., 2017) (Nsouli, et al., 2018) (Samdi & Qawasmeh, 2018) (Badarneh, et al., 2018).
Preprocessing tasks such as rule-based stemming and light stemming are optimized to be used in clustering. Many classification and clustering algorithms have been used to retrieve information from applications. Therefore, natural language processing (NLP) has been used to support name entities, question answering, and sentiment analysis (El-Nagga, et al., 2017). In addition, hybrid approach between modern standard Arabic and dialectal Arabic (e.g. Egyptian dialectal) should be needed for sentiment analysis.
Real time traffic events and road conditions with congestion attentions based on twitter data analysis, is one of the hot applications that support intelligent transportation system (ITS) (Nsouli, et al., 2018). The ‘ITS’ helps drivers to know shortest roads and avoid cars’ accidents based on (Abuaiadah, et al., 2017) traffic tweets post analysis.
A supervised machine learning method is announced to extract events for Arabic tweets. The proposed method in (Samdi & Qawasmeh, 2018) based on triggering event, time event and type of event. An Arabic tweets dataset is built and annotated by two human experts, in case of emotional analysis (Badarneh, et al., 2018); (Al-A’abed & Al-Ayyoub, 2016); (Hmeidi, et al., 2016). Emotional analysis focuses on emotion such as (joy, fear, happiness, sadness, surprise, anger, etc.). Also, lexicon-based approach is used to analyze Arabic children stories with their emotional expressions (El Gohary, et al., 2013). Accordingly, natural language processing (NLP), morphological, syntactic and semantic tasks with stemming task will be used in sentiment analysis.
The present paper has been divided into following. Section 2 introduces literature review with related works for sentiment analysis. Section 3 explains Arabic text analysis framework and describes the different design stages of all models. The classification model with machine model algorithms has been illustrated in section 4. Section 5 evaluates output results with accuracy indicators. Conclusion and future work is presented in section 6.
Sentiment and opinion mining of tweets are considered to be more interesting than documents mining. In addition, this mining is ambiguous and vague (Abuaiadah, et al., 2017); (Efron, 2011).Other challenging points to work with the sentiment analysis, opinion mining and the corresponding needed datasets are mentioned in many literatures (Oraby, et al., 2013). Therefore, it is significant to evaluate messages tweets on social networks as indicators of people opinions. An assistant opinion model with messages orientations are presented in (Nabil, et al., 2015); (Ibrahim, et al., 2015) to analyze and classify tweets in social media and documents analysis.
An improvement of aspect sentiment analysis has been presented in (Do, et al., 2019). Aspect extraction and tweets classifications of messages reviews for products are two objectives of this research. Therefore, machine learning approach with syntactic and semantic messages features are achieved.Word co-occurrence networks for microblogs have been presented to analyze and uncover hidden parameters (Garg & Kumar, 2018). Evaluation and experimental results have been done based on FSD dataset.
Ismail et al presented their work to analyze Arabic tweets dialected with Sudanese people to observe their opinions (Ismail, et al., 2018). Four classifiers (NB, SVM, K-Nearest and Multinomial logistic regression) were used in training with dataset includes 4712 tweets. The SVM classifier gave and revealed highest score with 72%.Alayba et al mentioned that the use of deep neural networks gauge to classify and analyze sentiment analysis and natural language processing applications (Alayba, et al., 2018). Therefore, Word2Vec model is described; and implemented by using a large Arabic corpus from ten newspapers. They reported that they obtained good accuracy of classification. Alharbi et al work introduced their paper to identify activities that led to Saudi citizens’ happiness. Entertainment events, Saudi cities, and happiness activities are used events to measure the happiness base on Twitter in Saudi Arabia (Alharbi, et al., 2018).
In Arabic countries, we have many dialectical languages, rather than “modern standard Arabic (MSA)”. In Saudi Arabia, six major dialectical regions exist (e.g. Hejazi, Najdi) (Alwakid, et al., 2017). Table 1 includes some examples to show differences between MSA and Saudi dialectical (Hejazi, and Najdi).
Table 1: Some Examples to Illustrates Differences Between MAS and Arabic Dialected Words (Alwakid, et al., 2017)
| English | Modern Standard Arabic | Dialected in Saudi | |
| Hejazi | Najdi | ||
| Window | نافذة | طاقه | شباك |
| Leave it | اتركها/دعها | سيبها | خلها |
| What | ماذا | ايش | وش |
Some troubles and difficulties such as understanding the concept and the meaning of dialectal language and related definitions need additional elaboration. The idea behind that is lexical units with similar meanings should appear in similar context. Therefore, official repository for semantic information for emotions’ content and sentiment orientation will be involved.
Arabic Text Analysis Framework Materials
The natural language processing (NLP) operations will be employed to understand the Arabic text tweets. Then text analysis step will take place. Different NLP operations will be explored in detail such as preprocessing with standard linguistic notation. Therefore, the preprocessing phase includes tokenization, tagging, chunking, stemming and lemmatization. Based on these operations, we obtain words, phrases and sentences or any other tokens. Text cleaning is also needed to increase the accuracy of the classifiers (e.g. normalizing text). Other important aspects should be involved such as syntactic structure and POS, parsing and grammars. The architecture of the proposed framework is illustrated in Figure 1.
Many preprocessing tasks and related models are needed to analyze messages in the following description. The pre-processing phase will be described in the following algorithm.
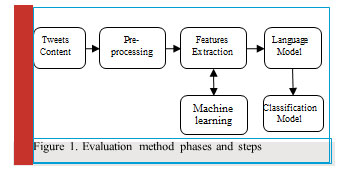 |
Figure 1: Evaluation method phases and steps |
Step 1. Given dataset as stream of tweets
Step 2. Splitting each tweet alone (Splitting algorithm)
Step 3. Clean each tweet from
HTTP link, and URLs for each tweet using regular expressing algorithm.
Non-Arabic words
Unnecessary and special characters
Diacritics and punctuation marks
Repetition of characters
Using Cleaning algorithm
Step 4. Tokenize each tweet by split algorithm.
Step 5. Apply Stemming process
Step 6. Apply the stop word algorithm.
Step 7. Return by the tweet
Language model
The objective of language model is to analyze and understand the content text in order to extract relevant information and create internal representation of the analyzed text. This internal representation is very important to understand the context meaning of the text. Consequently, the task of the language model includes tokenizer, morphological, syntactic and semantic analysis phases. Therefore, the language model uses a well-defined dictionary, lexicon and grammatical rules. The output results of language model is used to achieve the internal meaning (internal representation).
Tweets Corpus Tokenization Phase
This task splits Arabic tweets (text corpus) into pieces called tokens. The splitting task of tweets sentences is performed by using specific delimiters such as (“.”, “,”, “;”, and “n”). Therefore, many of Arabic tweets are needed to create our corpus to work with the natural language to work with the Arabic natural language toolkit. Next, tokenizer task tokenizes the Arabic text stream into separate words (tokens) using the pre-trained Arabic tokenizer and the NLTK interface.
The first step includes two sub-steps: sentence/phrase splitting, tokens (words) and word derivations with affixes processing. Any Arabic text content will be segmented into separate sentences/ phrases (chunks). After that, each sentence/phrase will be segmented into separate words (tokens). So, the morphological analyzer takes place to analyze and make derivations of the current word and remove affixes from it, and therefore, find its root. The affixes can be processed to find out additional parameters or indictors to support the word part of speech (verb, noun, character, etc.), gender, tense, number (singular or plural). Details of the preprocessing phase and the details of tokenizer module are shown in Figure 2.
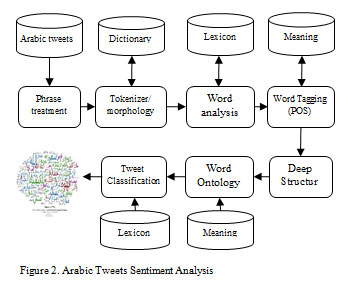 |
Figure 2: Arabic Tweets Sentiment Analysis |
Words Tokenization
This phase receives its input from tweets stream (previous task) and splits the segmented sentence into their component list of words (tokens). This process is important to clean and normalize the generated words (tokens) and extract root for each individual word. Any proposed word tokenizer includes the following steps:
Step 1. While there is a stream for tweets text Do
Step 1.1. Separate and split the input text stream out periods that exist at the end of each tweet.
Step 1.2. Separate and split the sentence stream when find out any delimiters followed by white spaces.
Step 1.3. Split words using standard root using contractions method.
Step 1.4. Employ the word tagging (POS) for the whole tweet.
Step 4. Stop.
This task will be applied before and after cleaning task. The root and/or stem will be recognized with different lexical indicators.
Next section describes the normalization tasks to get clean textual data that understand its meaning. The only thing we need is to maximize the Arabic tweets data to be very large. However, depending on how we plan to use our model, we need to be more or less satisfied with the quality of the dictionary and lexicon we use. Whenever there is doubt, the general rule is the more data we have, the better the case is. Moreover, depending on the corpus size (tweets content), training can take several hours or even days, but fortunately, and we can store the analyzed data and extracted features on a storage disk. Thus we do not have to perform the analyzed tasks of model training every time we use it.
Normalize Tweets
As illustrated in (Alwakid, et al., 2017), many challenges have been encountered to analyze Arabic tweets due to unstructured written language: orthographic errors, dialected words, ironic-sentences, contractions, idiomatic terminologies/ expressions, or abbreviations. Moreover, repetition of Arabic characters needs to be normalized (unified). Therefore, normalization is used to change some of special characters into one form (shape). Sometimes, Arabic letters (آ , أ, إ) can be changed into one form Arabic letter (ا), see table 2.
This process includes series of steps to clean, tokenize, standardize and wrangle tweets stream into a suitable form that could be processed by NLP various analytic methods.
Clean Tweets
Sometimes many of extraneous and unnecessary characters and tokens are not needed or not required, such as symbol tags and repeated data. Therefore, such unnecessary tags and repeated data can be removed. Removing unnecessary and special characters will be done before and after cleaning task.
Contraction Tweets
This task is important to avoid and recover the standard text of Arabic. Some contraction types can be classified into normal (auxiliary verb), negated, and colloquial. According to the Arabic tweets nature, the colloquial contraction with an acronyms or short end description (abbreviated), such as “د.” Means as “دكتور” and “أد” means “أستاذ دكتور” are two type of such contractions. Other types such as euphemism taboo word (restricted), vulgar and accepted will be discussed in other literatures.
Stem
Morpheme is the smallest unit in morphological analysis, it consists of stem and affixes. The stem is known as a base form of a word, and we can generate new words by attaching affixes to this base form. Therefore, the stem can be extracted from that inflection/derivation; a process known as stemming.
Al-Barhamtoshy et al. (Al-Barhamtoshy, et al., 2007) remarked that Arabic is a derivational and morphological language. The reason that allows several different patterns or surface forms or stem for single words. Table 3 describes examples of some cases.
Table 2: Some Examples to Illustrates Differences Between MAS and Arabic Dialected Words
| Letter process | Normalized letters | Examples | |
| ا أ إ ء آ | ا | إذا => اذا | إذا => اذا |
| ه ة | ه | جميلة => جميله | حلوة => حلوه |
| ى ي | ى | جري => جرى | علي => على |
Lemmatization
Lemmatization is similar to stemming after removing word affixes. It is the task of finding base form. Sometimes this base form needs to make extra inflection or derivational and lexicographical process to find correct word in the dictionary (root stem).
Ontology Phase
We are now moving from corpus data (unstructured data that include tweets’ messages) to deep structure or internal representation (semi structured data). If we know the tweets sender name, we also know in which country the sender lives; sender write tweets that are published in specific dates and written in a particular language, etc.
Table 3: Some examples to explain different surface forms
| Arabic Word | Forms | English meaning |
| ذهب | ذهب
ذُهِب أذهب أذهب؟ |
Gold
Painted Go Is this gold? |
| حب | حب
حُب أحب تحب يحب … |
Grain
Love I love You love He loves … |
There is a whole series of information to be drawn from this tweets story – this is the goal of the ontology. In addition, phonology helps us understand missing data. If the NLP analyst has recognized the sender and title, what has not been recognized? It seems that the tweet is published in group domain. So let’s look for history – it’s there. Moreover, it seems that the language is also involved – we can find it too.
The classification process is based on ontology within the Interlingua language model approach. The syntactic/semantic generation module with a very limited domain of classification (forecast ontology could support classification). Therefore, the ontological representation determines which route (meaning) to track and so, classify the words correctly.
classification of model architecture
Tweets Dataset
Arabic twitter can be used to create tweets dataset (dictionary and lexicon) of the proposed solution with classification model. Table 4 illustrates some examples that are selected from the created corpus. Some of this dataset is constructed and released, annotated for morphological and syntactic analysis, and others are used in clustering (Nabil, et al., 2015).
Many tweets representing judgement directions can be assigned to several categories of sentimentality. Primarily, these tweets are used to represent the tweets corpus. Tweets classification can be classified into two types: content-based and request-based classification.
To automate and create “tweets classification system”, we will classify tweets corpus to domain categories or classes.
Table 4: Tweets Dataset Description
| Dataset Title | Original Content | Words/ Tokens | Size |
| Arabic-Violence-Twitter | Voilence Keywords | Words | 237 |
| Emotion Icons | Icons | 800 | |
| Stop words | Words | 126 | |
| Arabic Sentiment Tweets Dataset | Train.txt | Tweets | 2002 |
| Test.txt | Tweets | 218 | |
| TripAdvisor.com | Attraction ATT.csv | Tweets (2154) | 893 KB |
| Qaym.com | Hotel HTL.csv | Tweets (15572) | 14.5 MB |
| Elcinemas.com | Movie MOV.csv | Tweets (1524) | 5.11 MB |
| Souq.com | Product PROD.csv | Tweets (4272) | 515 KB |
| TripAdvisor and Qaym | Resturant RES.csv | Tweets (10970) | 4.24 MB |
| MPQA-Ar | Training (CSV)
Testing(CSV) |
Tokens | 20430823153 |
| Astd-artwitter | Training (CSV)
Testing(CSV) |
Tokens | 42076
4519 |
| LABR-book-reviews | Training (CSV)
Testing(CSV) |
Tokens | 937765
99947 |
Usually, supervised and unsupervised machine learning algorithms are relevant to classify such input tweets. In addition, reinforcement and semi-supervised learning may be used.
To describe the classification process of tweets in scientific notation. The text tweets (TT) is a set of combined texts and labels. TT = { (T1, c1), (T2, c2) … ,( Tn, cn)} where, T1, T2,…, Tn, are a list of tweets, and their paired labels are classes: c1, c2, … , cn..
Assuming that the learning algorithm L is trained with the training dataset TT, the classifier φ such that F(TT)=φ is used. The workflow of the proposed automated tweets classification system is illustrated in Figure 3.
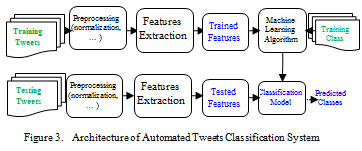 |
Figure 3: Architecture of Automated Tweets Classification System |
Usually, the dataset is divided into two datasets, training and testing datasets. The preprocessing phase and the features extraction phase are overlapped to be used in both training and testing. In the training phase, each tweet has its own equivalent type (category or class) that was labeled before. The cleaning tweets will be forwarded to the feature extraction phase to extract significant features (numeric arrays or vectors).
These significant features (vectors) are feeding with the corresponding related labels to the machine learning algorithm to learn various tweets patterns related to each category and combine classification model. This gained knowledge will be used to predict categories for new tweets. Once we have the classification model (working model), we can test such model using accuracy metrics.
Feature Extraction (Feature Engineering)
Features are measurable properties for every data element in a dataset. The feature extraction (engineering) is the process to transform the input stream of dataset into a set of measurable value (numerical values). These features can be extracted using machine learning algorithm in order to differentiate and recognize the tweet’s dataset.
“Vector Space Model” or “Term Vector Model” is used as mathematical model to represent tweets text as numeric vector. We have a tweet T in a tweet vector space VS. The dimension of each tweet is the number of distinct words for all tweets in the vector space.
VS= { W1, W2, … , Wn } ………………………. (1)
Where n represents distinct words in the whole tweets. We can represent tweet (T) in such vector space by:
T = { WT1 , WT2 , … , WTn } …………………… (2)
Where WTn describes the weight of word (n) in tweet (T). This weight represents frequency (or average frequency) as numeric value, or term frequency (TF) weight.
Evaluation of The Proposed Model
To evaluate the proposed work (Arabic sentiment analysis) through word embedding, precision, recall, accuracy and F1-score of tweets, classification will be used. Also, confusion matrix with detailed of the classification result will be used for performance measurement. Table 5 describes the analyzed results of our dataset. These analyzed data include the tokenized training dataset, and tokenized testing dataset. Then the vectorization process is employed with vectorized training tokens with 14803, and vectorized testing tokens with 1645.
We used six classifiers, Random-Forest, Stochastic Gradient Descent (SGD), Support Vector Machine (Linear-SVC), Nu-SVC, Logistic-Regression, and Gaussian-NB. Classification results of these methods are demonstrated in table 6.
Figure 4 illustrates the receiver operating characteristic (ROC) as a relation between sensitivity and specificity (true positive and false positive rates) for all cut-off points. So, if we have true positive 0.85, we have a probability of 0.15 of being wrong.
Table 5: Analysis Results of Tokenization and Vectorization
| Tweets Dataset | Method Approach | Number of Tokens | |
| Training | Testing | ||
| Mpqa-ar | Tokenization | 204561 | 22203 |
| Vectorization | 8996 | 1000 | |
| astd-artwitter-ar | Tokenization | 41420 | 5175 |
| Vectorization | 3187 | 355 | |
| LABR-book | Tokenization | 930364 | 107348 |
| Vectorization | 14803 | 1645 | |
| Products | Tokenization | 48859 | 5894 |
| Vectorization | 3841 | 427 | |
| Restaurant | Tokenization | 325170 | 37352 |
| Vectorization | 7527 | 837 | |
Table 6: (a) Mpqa-ar Dataset Evaluation Results
| Classification Approach | Average | Prec. | Recall | F1 |
| Random-Forest | 74.69 | 75.00 | 65.90 | 70.16 |
| SGD-Classifier | 76.49 | 76.86 | 68.42 | 72.40 |
| Linear-SVC | 74.54 | 76.46 | 69.11 | 72.60 |
| Nu-SVC | 74.74 | 71.17 | 72.31 | 71.74 |
| Logistic-Regression | 76.79 | 76.31 | 70.02 | 73.03 |
| Gaussian-NB | 69.95 | 72.62 | 55.84 | 63.13 |
Table 6: (b) Astd-arTwitter Dataset Evaluation Results
| Classification Approach | Average | Prec. | Recall | F1 |
| Random-Forest | 74.69 | 85.80 | 73.23 | 79.02 |
| SGD-Classifier | 82.71 | 87.03 | 81.31 | 84.07 |
| Linear-SVC | 80.24 | 86.78 | 76.26 | 81.18 |
| Nu-SVC | 83.29 | 87.98 | 81.31 | 84.51 |
| Logistic-Regression | 81.94 | 88.95 | 77.27 | 82.70 |
| Gaussian-NB | 74.01 | 80.11 | 71.21 | 75.40 |
Table 6: (c) Astd-artwitter Dataset Evaluation Results
| Classification Approach | Average | Prec. | Recall | F1 |
| Random-Forest | 78.29 | 85.80 | 73.23 | 79.02 |
| SGD-Classifier | 82.71 | 87.03 | 81.31 | 84.07 |
| Linear-SVC | 80.24 | 86.78 | 76.26 | 81.18 |
| Nu-SVC | 83.29 | 87.98 | 81.31 | 84.51 |
| Logistic-Regression | 81.94 | 88.95 | 77.27 | 82.70 |
| Gaussian-NB | 74.01 | 80.11 | 71.21 | 75.40 |
Table 6: (d) Restaurant Dataset Evaluation Results
| Classification Approach | Previous Results | Prec. | Recall | F1 |
| Random-Forest | 60.31 | 78.27 | 94.52 | 85.63 |
| SGD-Classifier | 65.48 | 80.36 | 92.91 | 86.18 |
| Linear-SVC | 71.92 | 84.16 | 89.86 | 86.92 |
| Nu-SVC | 69.08 | 82.09 | 92.27 | 86.88 |
| Logistic-Regression | 73.27 | 85.12 | 89.37 | 87.20 |
| Gaussian-NB | 51.30 | 86.78 | 41.22 | 55.90 |
Table 6: (e) Products Dataset Evaluation Results
| Classification Approach | Previous Results | Prec. | Recall | F1 |
| Random-Forest | 63.80 | 76.53 | 95.35 | 84.91 |
| SGD-Classifier | 75.48 | 82.13 | 94.68 | 87.96 |
| Linear-SVC | 76.92 | 83.99 | 92.36 | 87.98 |
| Nu-SVC | 71.08 | 79.89 | 95.02 | 86.80 |
| Logistic-Regression | 76.27 | 83.53 | 92.69 | 87.87 |
| Gaussian-NB | 63.30 | 88.27 | 57.48 | 69.62 |
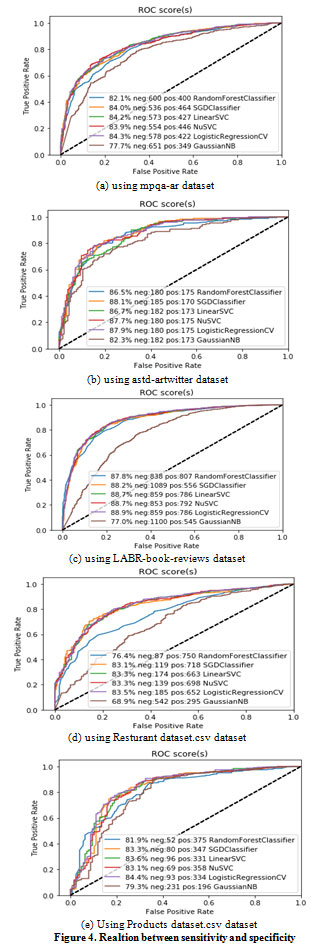 |
Figure 4: Realtion between sensitivity and specificity |
Conclusion
In this paper, we have presented a proposed model to analyze and classify Arabic tweets. The real application domain includes many of dataset in different domains. The proposed solution is tested with five corpora for Arabic tweets. The proposed model has been tested according to different six classifiers; the output results indicate that our model increased the accuracy of the sentiment classifications tasks in all the used datasets based on the language model.
Some difficulties such as understanding the concept and the meaning of dialects and related definitions need additional elaboration; the reason is that the lexical units that have similar meanings should appear in similar context. Therefore, official repository for semantic information for domains’ contents and terminologies definitions should be involved using ontological additional works.
References
Abuaiadah, D., Rajendran, D. & Jarrar, M., 2017. Clustering Arabic Tweets for Sentiment Analysis. Hammamet , IEEE, pp. 449-456.
Al-A’abed, M. & Al-Ayyoub, M., 2016. A lexicon-based approach for emotion analysis of arabic social media content. Amman, Jordan, ICSIC.
Alayba, A., Palade, V., England, M. & Iqbal, R., 2018. Improving Sentiment Analysis in Arabic Using Word Representation. Coventry, UK, ASAR, pp. 1-4.
Al-Barhamtoshy, H., Thabit, K. & Ba-Aziz, B., 2007. Arabic Language Template Grammars Component Based Technology. Cairo, Ain shams University, ESOLE, pp. 22-31.
Alharbi, A., Alotebii, H. & Almansour, A., 2018. Towards Measuring Happiness in Saudi Arabia based on Tweets: A research proposal. Riyadh, ICCAIS, pp. 1-4.
Alwakid, G., Osman, T. & Hughes-Roberts, T., 2017. Challenges in Sentiment Analysis for Arabic Social Networks. Procedia Computer Science, pp. 89-100.
Badarneh, O. et al., 2018. Fine-Grained Emotion Analysis of Arabic Tweets: A Multi-Target Multi-Label Approach. Laguna Hills, CA, ICSC, pp. 340-345.
Do, H., Prasad, P., Maag, A. & Alsadoon, A., 2019. Review: Deep Learning for Aspect-Based Sentiment Analysis: A Comparative Review. Expert Systems with Applications, pp. 272-299.
Efron, M., 2011. Information search and retrieval in microblogs, Information search and retrieval in microblogs. Journal Of The American Society For Information Science And Technology, 62(6), p. 996–1008.
El Gohary, A., Sultan, T., Hana, M. & El Dosoky, M., 2013. A computational approach for analyzing and detecting emotions in Arabic text. International Journal of Engineering Research and Applications (IJERA), pp. 100-107.
El-Nagga, N., El-Sonbaty, Y. & Abou El-Nasr, M., 2017. Sentiment Analysis of Modern Standard Arabic and Egyptian Dialectal Arabic Tweets. London, UK, IEEE, pp. 880-887.
Garg, M. & Kumar, M., 2018. The structure of word co-occurrence network for microblogs. Physica A: Statistical Mechanics and its Applications, pp. 698-720.
Hmeidi, I., Al-Ayyoub, M., Mahyoub, N. & Shehab, M., 2016. A lexicon based approach for classifying Arabic multi-labeled text. INTERNATIONAL JOURNAL OF WEB INFORMATION SYSTEMS, pp. 504-532.
Ibrahim, H., Abdou, S. & Gheith, M., 2015. Sentiment Analysis for Modem Standard Arabic and Colloquial. International Journal on Natural Language Computing (IJNLC), pp. 95-109.
Ismail, R. et al., 2018. Sentiment Analysis for Arabic Dialect Using Supervised Learning. Khartoum, ICCCEEE, pp. 1-6.
Nabil, M., Aly, M. & Atiya, A., 2015. ASTD:Arabic Sentiment Tweets Dataset. Lisbon, Purtogal, Association for Computational Linguistics, p. 2515–2519.
Nsouli, A., Mourad, A. & Azar, D., 2018. Towards Proactive Social Learning Approach for Traffic Event Detection based on Arabic Tweets. Chicagou, IWCMC, pp. 1501-1506.
Oraby, S., El-Sonbaty, Y. & Abou El-Nasr, M., 2013. Exploring the effects of word roots for arabic sentiment analysis. International Joint Conference on Natural Language Processing, p. 471–479.
Samdi, M. & Qawasmeh, O., 2018. A Supervised Machine Learning Approach for Events Extraction out of Arabic Tweets. Valencia , SNAMS, pp. 114-119.

